对于进程、线程、协程这三个概念都是简单了解原理,然后用的时候调库就行了,这样总归还是不太好。所以今天就详细探讨一下Python中的这几个概念,并且用代码来实现一遍,体现出他们的差异,然后还得涉及到Python中的GIL锁。
概念
- 为何引入这些概念
我们知道,早期的计算机性能其实很鸡肋,单核心的处理器,同时只能运行一个任务。但是这样有个缺点,假如有个任务执行要耗时很长,我们想运行另一个耗时很短的任务岂不是要等很久。于是我们引入并行和并发两个概念。对于现在手机都到了4核起步,8核12核都不少见的情况,我们运行多任务当然没啥问题。但是对于早期的单核,我们也想要运行多个任务怎么办,能不能让每个任务执行一小会就换到另外一个任务呢,这时就提出了并发的概念,就是多个任务之间交替发生。而并行则是指多个任务同时进行,这只能出现在多核处理器上。下面我们就并发和并行做个简单介绍与区分。- 并发:
并发是个宏观上能同时处理多任务,微观上同时只能处理一个任务的概念。上面说了,并发是在单核CPU上体现出来的。任务之间在一个微小的时间里交替发生,而在一个大的时间范围内我们看上去好像就是并行一样。 - 并行:
并行就是一个微观宏观上都是同时处理多任务的情况。这些多任务完全处于不同的CPU,当然互不影响。
- 并发:
并发和并行这两个概念都是为了多任务而出现。区别的话举个例子,你吃小金橘。你剥完一个皮之后放嘴里,吃完之后又拿一个,我们可以说你同时吃了多个橘子,但是这叫并发(某个时间段内同时发生)。你一遍剥一边吃,嘴里还没吃完手上已经剥好了,这样你也叫同时吃多个橘子,但是你这叫并行(某个时间点同时进行)。看到了没,一般来说并行还是比并发快的,这也就是为什么同样的处理速度下,利用多核程序会比较快的原因。放个图直观感受下。
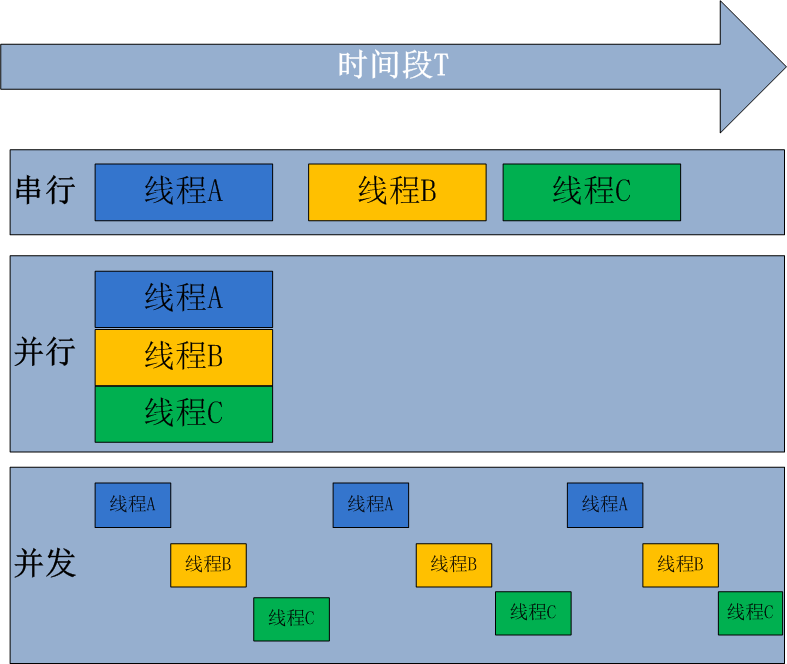
- 进程线程协程之间的关系
首先,我们要明白,我们写的代码程序只是一个静态的存在。丢在硬盘里和txt文档一样没有什么多大的作用。只有当程序跑起来才会利用cpu进行各种操作,获得神奇的运算输出。而当程序运行时,会产生一个叫进程的东西,这个东西是动态的。进程是计算机资源分配的基本单位,而一个进程又由至少一个线程组成,是计算机调度的最小单位,多个线程之间共享分配到进程的资源,可以交替执行。而协程则是可以分属于一个线程中的代码片段,利用协程我们可以使得单个线程中不同代码片段之间交互进行。所以,利用进程线程协程之间的概念,我们就能实现上面所说的并行与并发。
进程(Process)
上面说了,进程是计算机资源分配的基本单位。计算机在程序启动时,对于程序所要求的内存,磁盘,寄存器,文件指针都是由操作系统分配到进程。他是一个动态的实体。进程由程序,数据集,PCB进程控制块组成。程序是描述进程具有完成什么功能的作用;数据集是程序在执行过程中所要消耗的资源;进程控制块是用来保存程序运行的状态。进程有三大状态,就绪态,运行态和阻塞态。这几个状态之间的转换在操作系统的课本上讲的滚瓜烂熟了,这里就不再重复。贴个图自行体会。
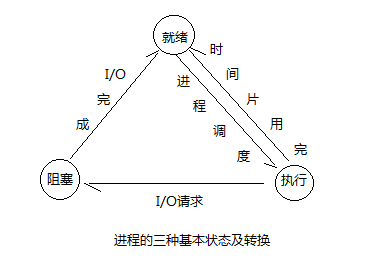
线程(Thread)
线程是计算机进行调度的最小单位,每个进程下面拥有至少一个线程,多个线程之间共享同一进程所分配到的资源(不同进程之间的线程是隔离的)。但是线程也有一些诸如线程ID,私有栈等,不过堆是共享的。所以线程是进程的一个子概念。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。而且一个进程的多个线程可以在多个核上跑(CPython这种带GIL锁的以后再详细探讨)。
协程(Coroutine)
协程的话就是一个线程下的子概念了。协程也叫微线程,纤程。我们知道,单独一个线程中,代码的执行也是有序的,你必须得一个函数一个函数按序执行。但是如果当前有个等待事件(比如键盘输入)需要等待可能耗时很长的一个过程,那我能不能利用这个时间去干点别的事情呢,比如运行一下另一个函数中的简单计算?当然可以,利用协程就可以做到。这里要明白一下,你要是普通地切换另一个函数执行,那当前这个函数就被出栈了,因此你的现场数据不会被保存,而利用协程则会保护现场数据。
GIL锁
首先要明确的一点就是,GIL锁他并不是Python的特性,而是Python解释器CPython引入的一个概念(CPython是python默认的解释器)。为了利用多核Python支持了多线程,而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁,于是有了GIL这把超级大锁(默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。GIL无疑就是一把全局排他锁,对多线程的效率有不小影响,所以CPython中的多线程和单线程简直没啥区别。因此,现在的情况一般都是多进程+协程来使用。
实践
好了,概念啰嗦了一大堆,是时候表演真正的技术了。
进程
这里有个子进程的概念要了解下,别把子进程和线程搞混。子进程是父进程fork出来的一个东西,当父进程把一些东西设置好,新建一个进程实体后,两者算是基本独立,就儿子成家后和老爸的区别,但是两者还是可以通信。
- 启动进程
在python中的multiprocessing包中定义了Process类,所以我们在开启一个进程的时候对类的实例化可以有两种处理方式,直接实例化和继承再复写。
1 | |
输出
1 | |
这里我把方式一的sleep设置为了300s,所以看得能明白些。可以看到橘子进程已经完成了,而香蕉进程因为sleep太久而被卡住,这时在任务管理器中也能看出来进程数是多了的。
- 方法介绍
1 | |
线程
Python中对线程也进行了封装,我们直接使用Thread这个包即可。类比上面进程的代码,其实使用起来非常相似,但是要注意这是封装的结果,他们的性质还有有区别的。
1 | |
输出
1 | |
注意这里多运行几次,因为线程共享了进程的资源,所以实体化与切换线程的过程是十分迅速的,线程之间进行切换所进行的资源消耗远低于多进程,所以你会看到每次运行都是几乎相同的结果。还注意到,所有线程的进程ID和父进程ID都是相同的。但是为什么每次父进程ID都是一样的呢,我又查了一下,发现这个其实是终端进程的ID,只要你当前终端没有终止,执行的话就一直是这个ID。
- 方法介绍
1 | |
协程
如果说进程和线程都是由CPU控制的相互切换,那么协程就是代码内由程序猿自己控制的切换过程了。由于也是在同一线程内,所以几乎不消耗切换的时间与资源,唯一可能消耗的一点就是暂存的现场栈数据了。这里我们用几个方法来实现一下。
- yield实现
1 | |
输出
1 | |
yield是python中的生成器,生成器与迭代器以前讲过了,大体也有个印象,以后有时间再详说。看代码和输出,我们可以知道,代码在两个函数中交替执行。并且还会保存现场数据,不会像普通方法一样每次都要重新开头执行。这里值得注意的一点,函数中只要出现了yield,函数就是一个生成器了,所以你执行func(),yield前面的代码也不会执行,必须要send或者next才会启动生成器,而且send函数开始不能send非None值,并且每次只能send一个参数。
- greenlet实现
1 | |
greenlet主要是通过栈的复制切换来实现不同协程之间的切换,有时间可以好好读读源码了解一下。另外还有对greenlet的封装库,eventlet和gevent实现。Eventlet在Greenlet的基础上实现了自己的GreenThread,但是具有自己的Hub调度器,并且还对python的标准库打了补丁来实现“绿化操作”。Gevent也是对greenlet的封装,我目前在网上查到的资料是利用libev(linux下的包)进行高效调度,遇到IO操作时会自动切换,但是我实验的时候win下是可以用的,并且安装pip包的时候出现了ys_platform == "win32" and platform_python_implementation == "CPython" (from gevent)的字样,所以应该是后来实现了,至于具体的实现以后看源码再说吧。
总结
线程、进程、协程的关系区别就暂时介绍到这里,不过还远远没有介绍完。在学习的过程中,还遇到了诸如锁、同步互斥的实现(线程间由于共享数据,不加锁很容易出岔子)、eventlet与gevent如何实现的协程调度,python3中的asyncio极其衍生的async/await、守护进程与守护线程、外部进程与僵尸进程与孤儿进程、进程与线程池等等很多概念。好像挖了很多坑,以后慢慢填吧(不过我哇进程线程协程的坑是为了填我接下来想说的RPC啊,好像坑越挖越深了怎么办。。。)。